Agile Transformation
Redesign organizational structures and create a culture that’s built for optimal value delivery

Organizations must be ready to conquer external and internal challenges that lead to loss of market share or make them unable to capitalize on new market opportunities. Agile Velocity works with teams who struggle to deliver on time and on budget, leaders who need a faster way to prioritize and make strategic decisions, and cost centers that need to transform into value providers.
Redesign organizational structures and create a culture that’s built for optimal value delivery
Pragmatic approach to implement the right parts of SAFe to achieve your desired results

Provide clarity and focus to deliver the most important strategic investments

Fill gaps in practices and behaviors to improve team performance

Certification and customizable Agile training onsite or remote for any role

Improve the engagement and performance of hybrid or remote teams

Our network combined with a rigorous recruiting process ensures you’re matched with coaches who make the journey successful and fun. And what’s more fun than winning?
 Eric brings sanity to your portfolio management capabilities, a pragmatic approach, and a bias toward action Eric brings sanity to your portfolio management capabilities, a pragmatic approach, and a bias toward action |
 David brings a business strategy and fiscal responsibility lens to your transformation with fun and positivity David brings a business strategy and fiscal responsibility lens to your transformation with fun and positivity |
 Bhavani brings thought leadership, empathy, and practical and tangible result Bhavani brings thought leadership, empathy, and practical and tangible result |
 Randy brings visibility into existing structures and performance measures that impede effectiveness Randy brings visibility into existing structures and performance measures that impede effectiveness |

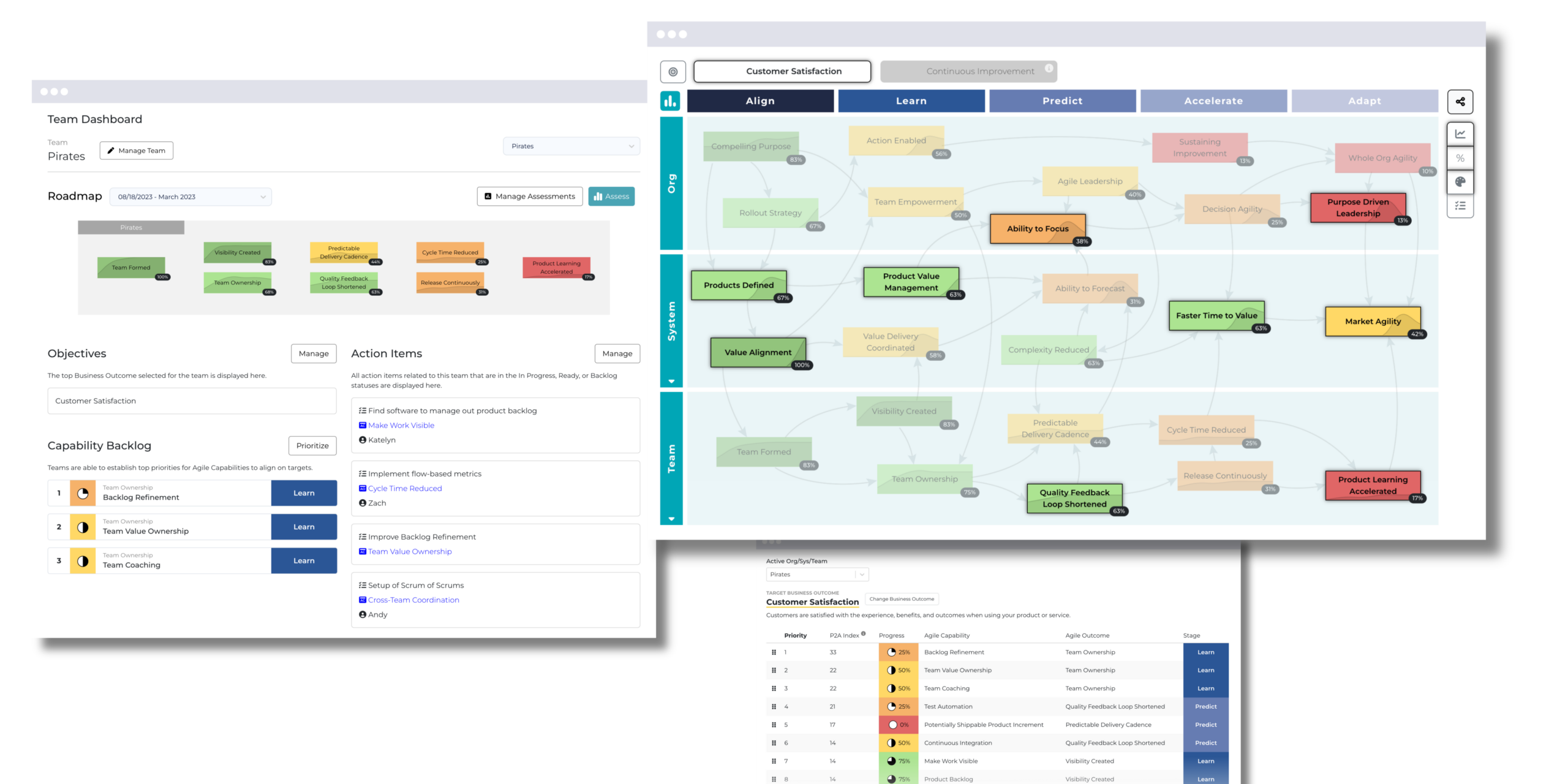
The vast majority of organizations who want organizational agility will either experience “superficial agility” or “pocket agility.” With both scenarios, it is easy for teams to revert back to ineffective behaviors. We created the Path to Agility® to solve these problems for organizations who need a consistent, flexible, and proven approach to organizational agility. Learn more about the model and our software product, Path to Agility Navigator.

“At the Executive level, Agile Velocity was key in turning around our transformation focus and propelling it forward.”
“Before working with Agile Velocity we never finished a sprint. We are now completing sprints consistently and pulling in additional work.”

“We accelerated through our transition with Agile Velocity’s help. The Path to Agility was crucial to our journey because it focused on outcomes, strengthened our capabilities, and became an integral part of our improvement mindset.”

“[The best part about our transformation] once we got out of the bottom of the change curve, the energy fundamentally changed. There’s something about having things on the wall, having standups, and operating differently that they were able to take ownership in a way they never had the context to do well before. It was exciting and felt good to be around.”
“Our culture has changed significantly. We are a good place to work. We were voted one of the best places to work in Texas. But within IT, we were very siloed. Teams didn’t interact with each other, and we didn’t interact as much with our onsite business customers. But, now what you see is that buzz and energy. Everybody is really focused on collaboration and tackling things together.”
“I was impressed with Agile Velocity's ability to quickly come up to speed, gain trust from the Southwest Teams and begin to partner in driving our transformation. They used the Path to Agility which drove alignment on goals, necessary actions, and focus areas as well as helped us track and visualize maturity. Their coaching enabled our teams to pivot and re-prioritize work in a quick and organized manner.”
Let’s have a conversation about how your organization can deliver value faster, with better quality, and more predictably.
Get Started